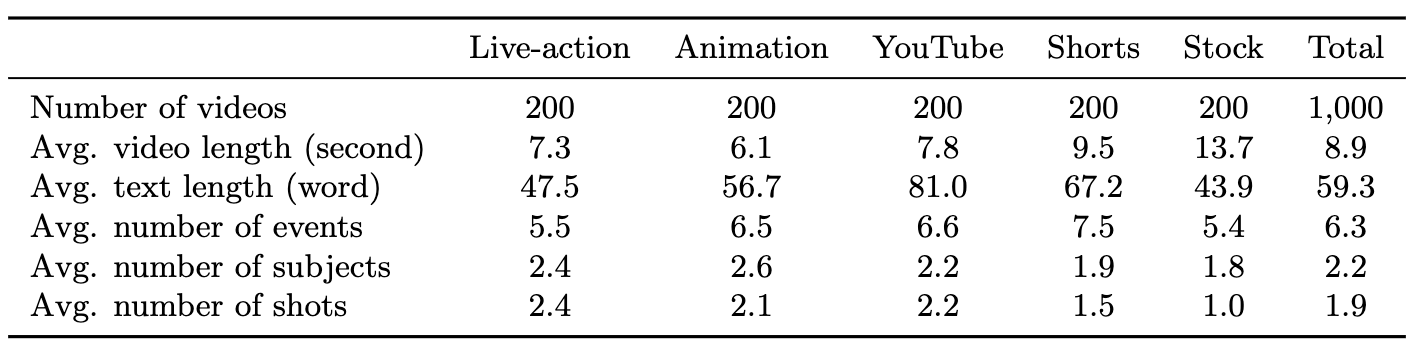
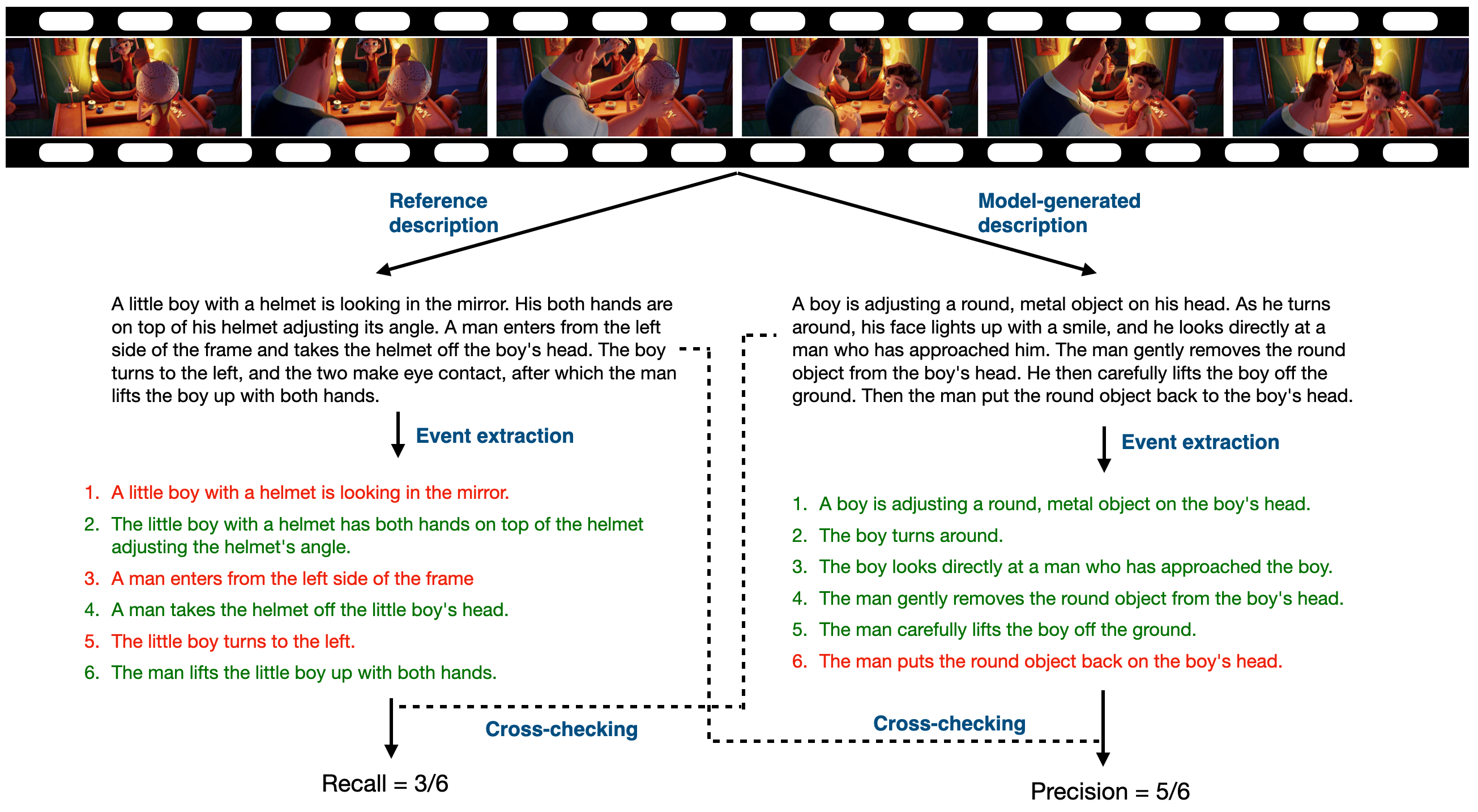
LM: Live-action movies AM: Animation movies ST: Stock videos YT: YouTube videos TT: TikTok-style short videos
F1: F1 score P: Precision score R: Recall score
By default, this leaderboard is sorted by overall F1 score, with overall Precision score as a secondary sort key. To view other sorted results, please click on the corresponding cell.
| # | Model | LLM Params |
Frames | Date | Overall (%) | LM (%) | AM (%) | ST (%) | YT (%) | TT (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | |||||
| Tarsier2-7B-0115
Bytedance Research |
7B | 16 | 2025/01/15 | 42.0 | 42.8 | 41.1 | 44.4 | 41.9 | 47.3 | 39.3 | 39.5 | 39.1 | 45.7 | 45.4 | 46.0 | 36.0 | 38.4 | 33.9 | 43.7 | 48.9 | 39.4 | |
| Tarsier2-Recap-7B
Bytedance Research |
7B | 16 | 2025/02/12 | 40.7 | 42.0 | 39.5 | 44.3 | 43.7 | 44.8 | 36.4 | 37.4 | 35.5 | 45.4 | 43.9 | 47.1 | 34.3 | 36.5 | 32.3 | 42.6 | 48.6 | 37.9 | |
| Tarsier2-7B-1105
Bytedance Research |
7B | 16 | 2024/11/05 | 40.1 | 41.5 | 38.8 | 43.8 | 43.1 | 44.5 | 37.1 | 37.2 | 37.1 | 43.9 | 44.2 | 43.6 | 34.5 | 37.7 | 31.8 | 40.9 | 45.5 | 37.1 | |
| GPT-4o
OpenAI |
- | 16 | 2024/05/13 | 39.2 | 43.4 | 35.7 | 39.8 | 42.1 | 37.8 | 35.8 | 39.1 | 33.1 | 44.0 | 46.6 | 41.7 | 35.9 | 41.5 | 31.7 | 39.9 | 47.9 | 34.2 | |
| Tarsier-34B
Bytedance Research |
34B | 8 | 2024/07/04 | 36.3 | 41.4 | 32.4 | 38.5 | 39.6 | 37.5 | 32.2 | 35.8 | 29.2 | 41.7 | 46.4 | 37.8 | 34.5 | 41.1 | 29.7 | 34.0 | 44.1 | 27.7 | |
|
Gemini 1.5 Pro
|
- | 1 fps | 2024/05/15 | 36.2 | 37.6 | 34.8 | 36.4 | 36.4 | 36.4 | 30.7 | 31.8 | 29.7 | 42.2 | 40.7 | 43.8 | 34.0 | 36.7 | 31.6 | 37.0 | 42.4 | 32.7 | |
|
Gemini 1.5 Flash
|
- | 1 fps | 2024/05/15 | 34.8 | 37.9 | 32.1 | 34.8 | 36.4 | 33.3 | 29.2 | 32.5 | 26.5 | 39.4 | 39.7 | 39.1 | 34.3 | 38.6 | 30.9 | 35.6 | 42.4 | 30.7 | |
| GPT-4V
OpenAI |
- | 8 | 2023/09/25 | 34.4 | 40.8 | 29.7 | 34.8 | 39.2 | 31.3 | 27.4 | 31.9 | 24.0 | 40.7 | 46.7 | 36.1 | 33.8 | 40.1 | 29.2 | 34.8 | 46.1 | 28.0 | |
| GPT-4o mini
OpenAI |
- | 8 | 2024/07/18 | 34.0 | 37.4 | 31.2 | 34.5 | 36.6 | 32.7 | 28.9 | 32.6 | 26.0 | 37.9 | 37.9 | 38.0 | 33.5 | 37.5 | 30.2 | 34.7 | 42.4 | 29.3 | |
| LLaVA-Video
Bytedance & NTU S-Lab |
72B | 32 | 2024/09/02 | 34.0 | 37.3 | 31.3 | 33.5 | 36.3 | 31.1 | 28.6 | 31.7 | 26.1 | 39.3 | 41.1 | 37.6 | 32.8 | 34.7 | 31.1 | 35.7 | 42.8 | 30.6 | |
| VILA-1.5
NVIDIA & MIT |
34B | 8 | 2024/05/01 | 33.2 | 37.6 | 29.7 | 34.1 | 34.3 | 33.8 | 27.1 | 30.3 | 24.5 | 38.4 | 41.7 | 35.6 | 33.7 | 38.6 | 29.9 | 31.5 | 43.2 | 24.8 | |
| Qwen2-VL
Alibaba |
72B | 2 fps | 2024/08/30 | 33.2 | 37.3 | 29.9 | 32.1 | 33.7 | 30.6 | 27.6 | 32.6 | 23.9 | 41.1 | 41.2 | 41.1 | 32.0 | 38.1 | 27.7 | 32.1 | 41.0 | 26.4 | |
|
LLaVA-OneVision
Bytedance & NTU S-Lab |
72B | 16 | 2024/08/06 | 33.2 | 35.9 | 30.9 | 31.7 | 32.8 | 30.7 | 27.7 | 30.6 | 25.2 | 38.0 | 39.6 | 36.6 | 34.1 | 34.7 | 33.5 | 33.8 | 41.8 | 28.4 | |
| LLaVA-Video
Bytedance & NTU S-Lab |
32B | 32 | 2024/09/02 | 32.9 | 34.4 | 31.6 | 32.2 | 32.2 | 32.2 | 28.5 | 29.4 | 27.7 | 38.2 | 38.4 | 37.9 | 31.3 | 33.9 | 29.1 | 34.2 | 38.2 | 30.9 | |
| LLaVA-Video
Bytedance & NTU S-Lab |
7B | 32 | 2024/09/02 | 32.5 | 37.9 | 28.4 | 31.4 | 35.2 | 28.4 | 27.6 | 32.9 | 23.8 | 36.7 | 39.7 | 34.1 | 33.0 | 39.5 | 28.3 | 33.4 | 42.5 | 27.5 | |
| InternVL2
Shanghai AI Lab |
72B | 8 | 2024/07/18 | 31.7 | 38.7 | 26.9 | 33.0 | 36.2 | 30.3 | 24.0 | 29.4 | 20.2 | 38.7 | 45.2 | 33.8 | 30.1 | 38.2 | 24.8 | 32.3 | 44.2 | 25.4 | |
|
LLaVA-OneVision
Bytedance & NTU S-Lab |
7B | 16 | 2024/08/06 | 31.7 | 34.3 | 29.4 | 31.2 | 33.2 | 29.3 | 26.8 | 29.0 | 25.0 | 38.1 | 39.1 | 37.1 | 30.6 | 32.1 | 29.2 | 31.4 | 38.3 | 26.6 | |
| Claude 3.5 Sonnet
Anthropic |
- | 16 | 2024/06/20 | 31.2 | 36.5 | 27.3 | 29.1 | 34.0 | 25.4 | 26.7 | 33.4 | 22.3 | 35.9 | 37.4 | 34.5 | 30.6 | 37.2 | 25.9 | 33.4 | 40.4 | 28.5 | |
| MiniCPM-V 2.6
OpenBMB |
7B | 64 | 2024/08/05 | 30.5 | 33.5 | 27.9 | 30.5 | 33.8 | 27.7 | 24.8 | 27.8 | 22.5 | 35.4 | 35.8 | 35.0 | 29.5 | 31.3 | 28.0 | 31.6 | 38.9 | 26.5 | |
| VILA-1.5
NVIDIA & MIT |
7B | 8 | 2024/05/01 | 29.9 | 35.4 | 25.8 | 29.2 | 32.1 | 26.8 | 23.9 | 30.0 | 19.9 | 35.1 | 38.2 | 32.5 | 31.7 | 37.1 | 27.7 | 28.5 | 39.5 | 22.3 | |
| Qwen2-VL
Alibaba |
7B | 2 fps | 2024/08/30 | 29.6 | 33.9 | 26.3 | 27.7 | 32.5 | 24.2 | 22.2 | 28.0 | 18.4 | 37.0 | 36.1 | 38.0 | 30.7 | 35.5 | 27.0 | 29.1 | 37.6 | 23.8 | |
| VITA
Tencent Youtu Lab & NJU |
8×7B | 16 | 2024/08/12 | 28.9 | 40.2 | 22.6 | 30.3 | 39.1 | 24.7 | 22.6 | 31.3 | 17.7 | 35.6 | 46.7 | 28.7 | 28.1 | 39.9 | 21.7 | 27.5 | 44.2 | 20.0 | |
| PLLaVA
Bytedance & NUS & NYU |
34B | 16 | 2024/04/24 | 28.2 | 38.4 | 22.3 | 29.3 | 34.9 | 25.2 | 20.9 | 32.0 | 15.6 | 35.1 | 42.5 | 29.9 | 28.9 | 40.8 | 22.3 | 25.6 | 41.9 | 18.4 | |
| VideoLLaMA 2
Alibaba |
72B | 16 | 2024/08/14 | 27.1 | 30.8 | 24.2 | 27.3 | 29.3 | 25.6 | 19.7 | 21.7 | 18.1 | 33.9 | 37.0 | 31.3 | 27.7 | 33.0 | 23.8 | 26.5 | 33.1 | 22.1 | |
| InternVL2
Shanghai AI Lab |
7B | 8 | 2024/07/18 | 26.9 | 29.5 | 24.7 | 27.3 | 27.4 | 27.1 | 20.6 | 23.8 | 18.1 | 33.3 | 33.5 | 33.0 | 26.9 | 30.2 | 24.2 | 25.7 | 32.7 | 21.2 | |
| VideoChat2-Mistral
Shanghai AI Lab |
7B | 16 | 2024/05/22 | 26.6 | 31.0 | 23.3 | 26.0 | 28.1 | 24.3 | 18.8 | 23.9 | 15.5 | 33.2 | 33.6 | 32.7 | 27.3 | 32.7 | 23.4 | 26.5 | 36.8 | 20.7 | |
| VideoLLaMA 2
Alibaba |
7B | 16 | 2024/06/06 | 26.2 | 31.5 | 22.4 | 25.1 | 28.7 | 22.2 | 20.4 | 25.5 | 17.0 | 32.6 | 35.5 | 30.2 | 27.5 | 33.5 | 23.4 | 24.5 | 34.1 | 19.2 | |
| Video-LLaVA
PKU |
7B | 8 | 2024/06/15 | 20.4 | 28.1 | 16.0 | 19.4 | 24.3 | 16.2 | 15.3 | 21.2 | 11.9 | 27.0 | 33.5 | 22.7 | 21.2 | 31.9 | 15.8 | 18.5 | 29.4 | 13.5 | |
| ShareGPT4Video
Shanghai AI Lab |
8B | 16 | 2024/06/11 | 19.5 | 26.6 | 15.4 | 19.8 | 27.8 | 15.4 | 14.8 | 22.8 | 10.9 | 25.2 | 28.9 | 22.4 | 19.1 | 26.2 | 15.0 | 18.0 | 27.3 | 13.4 | |
Date: indicates the publication date of open-source models -: indicates "unknown" for closed-source models